
Exploratory Grasping: Asymptotically Optimal Algorithms for Grasping Challenging Polyhedral Objects
Michael Danielczuk*, Ashwin Balakrishna*, Daniel S. Brown, Shivin Devgon, Ken Goldberg
Conference on Robot Learning (CoRL), 2020.
[PDF] [Presentation] [Website] [Code] [Bibtex]
Abstract
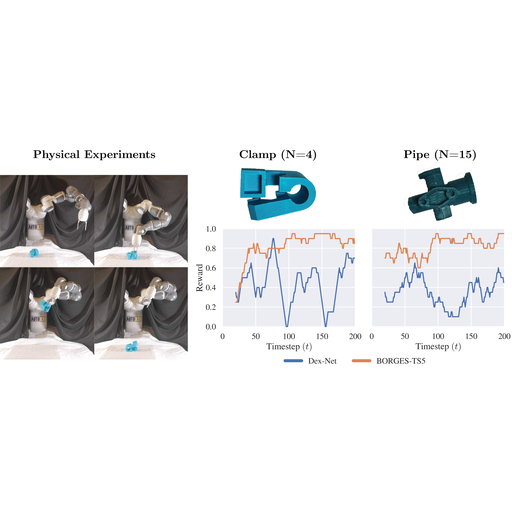
There has been significant recent work on data-driven algorithms for learning general-purpose grasping policies. However, these policies can consistently fail to grasp challenging objects which are significantly out of the distribution of objects in the training data or which have very few high quality grasps. Motivated by such objects, we propose a novel problem setting, Exploratory Grasping, for efficiently discovering reliable grasps on an unknown polyhedral object via sequential grasping, releasing, and toppling. We formalize Exploratory Grasping as a Markov Decision Process, study the theoretical complexity of Exploratory Grasping in the context of reinforcement learning and present an efficient bandit-style algorithm, Bandits for Online Rapid Grasp Exploration Strategy (BORGES), which leverages the structure of the problem to efficiently discover high performing grasps for each object stable pose. BORGES can be used to complement any general-purpose grasping algorithm with any grasp modality (parallel-jaw, suction, multi-fingered, etc) to learn policies for objects in which they exhibit persistent failures. Simulation experiments suggest that BORGES can significantly outperform both general-purpose grasping pipelines and two other online learning algorithms and achieves performance within 5% of the optimal policy within 1000 and 8000 timesteps on average across 46 challenging objects from the Dex-Net adversarial and EGAD! object datasets, respectively. Initial physical experiments suggest that BORGES can improve grasp success rate by 45% over a Dex-Net baseline with just 200 grasp attempts in the real world. See https://tinyurl.com/exp-grasping for supplementary material and videos.