
One-Shot Shape-Based Amodal-to-Modal Instance Segmentation
Andrew Li, Michael Danielczuk, Ken Goldberg
IEEE Conference on Automation Science and Engineering (CASE), 2020.
Abstract
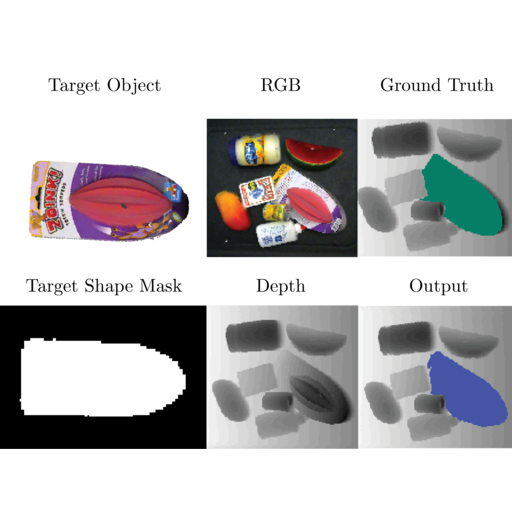
Image instance segmentation plays an important role in mechanical search, a task where robots must search for a target object in a cluttered scene. Perception pipelines for this task often rely on target object color or depth information and require multiple networks to segment and identify the target object. However, creating large training datasets of real images for these networks can be time intensive and the networks may require retraining for novel objects. We propose OSSIS, a single-stage One-Shot Shape-based Instance Segmentation algorithm that produces the target object modal segmentation mask in a depth image of a scene based only on a binary shape mask of the target object. We train a fully-convolutional Siamese network with 800,000 pairs of synthetic binary target object masks and scene depth images, then evaluate the network with real target objects never seen during training in densely-cluttered scenes with target object occlusions. OSSIS achieves a one-shot mean intersection-over-union (mIoU) of 0.38 on the real data, improving on filter matching and two-stage CNN baselines by 21% and 6%, respectively, while reducing computation time by 50 times as compared to the two-stage CNN due in part to the fact that OSSIS is one-stage and does not require pairwise segmentation mask comparisons.